微服務架構中的數據依賴問題及其解決方案
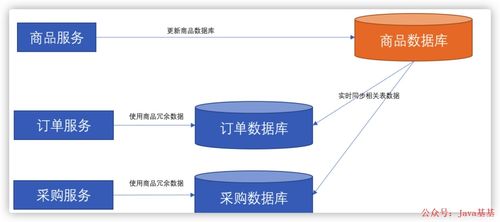
在微服務架構中,各服務獨立部署,但業務上往往存在數據依賴關系,這可能會導致數據不一致、性能瓶頸和系統復雜度增加等問題。以下是一些常見的解決方案:
1. API 調用與數據同步
通過定義清晰的 API 接口,微服務可以在需要時調用其他服務獲取數據。這種方式簡單直接,但需要注意網絡延遲和錯誤處理,以避免級聯故障。
2. 事件驅動架構
使用消息隊列(如 Kafka、RabbitMQ)發布數據變更事件,依賴方監聽事件并更新本地數據副本(如讀模型)。這樣可以解耦服務,提高系統的響應性和可擴展性。
3. 數據副本與緩存
在服務內部緩存常用依賴數據,通過定期同步或事件驅動更新緩存。例如使用 Redis 緩存數據,減少實時 API 調用,提升性能。
4. CQRS(命令查詢職責分離)模式
將寫操作和讀操作分離,讀服務可以維護自己的數據視圖,通過訂閱事件保持數據同步,從而避免直接依賴其他服務的數據庫。
5. 數據所有權與邊界上下文
明確每個微服務的數據所有權,遵循領域驅動設計(DDD)原則,確保數據變更僅通過服務接口進行,避免服務間直接訪問數據庫。
6. Saga 模式
對于跨多個服務的業務事務,使用 Saga 模式管理分布式事務,通過一系列本地事務和補償操作來保證最終一致性。
7. 數據聚合服務
引入一個專門的數據聚合服務,負責從多個微服務中獲取并整合數據,為前端或其他服務提供統一的數據視圖。
在實際應用中,通常需要根據業務場景、一致性要求和性能需求,組合使用上述方案。例如,高實時性要求的場景可能優先選擇 API 調用,而對一致性要求不高的場景可以使用事件驅動和緩存。同時,監控和日志記錄對于排查數據依賴引發的問題至關重要。
解決微服務數據依賴的關鍵在于平衡一致性、可用性和系統復雜度,通過合適的架構模式和工具實現松耦合、高內聚的微服務系統。
如若轉載,請注明出處:http://m.planethome.cn/product/36.html
更新時間:2026-01-07 00:46:52